Go Runtime Inside Architecture

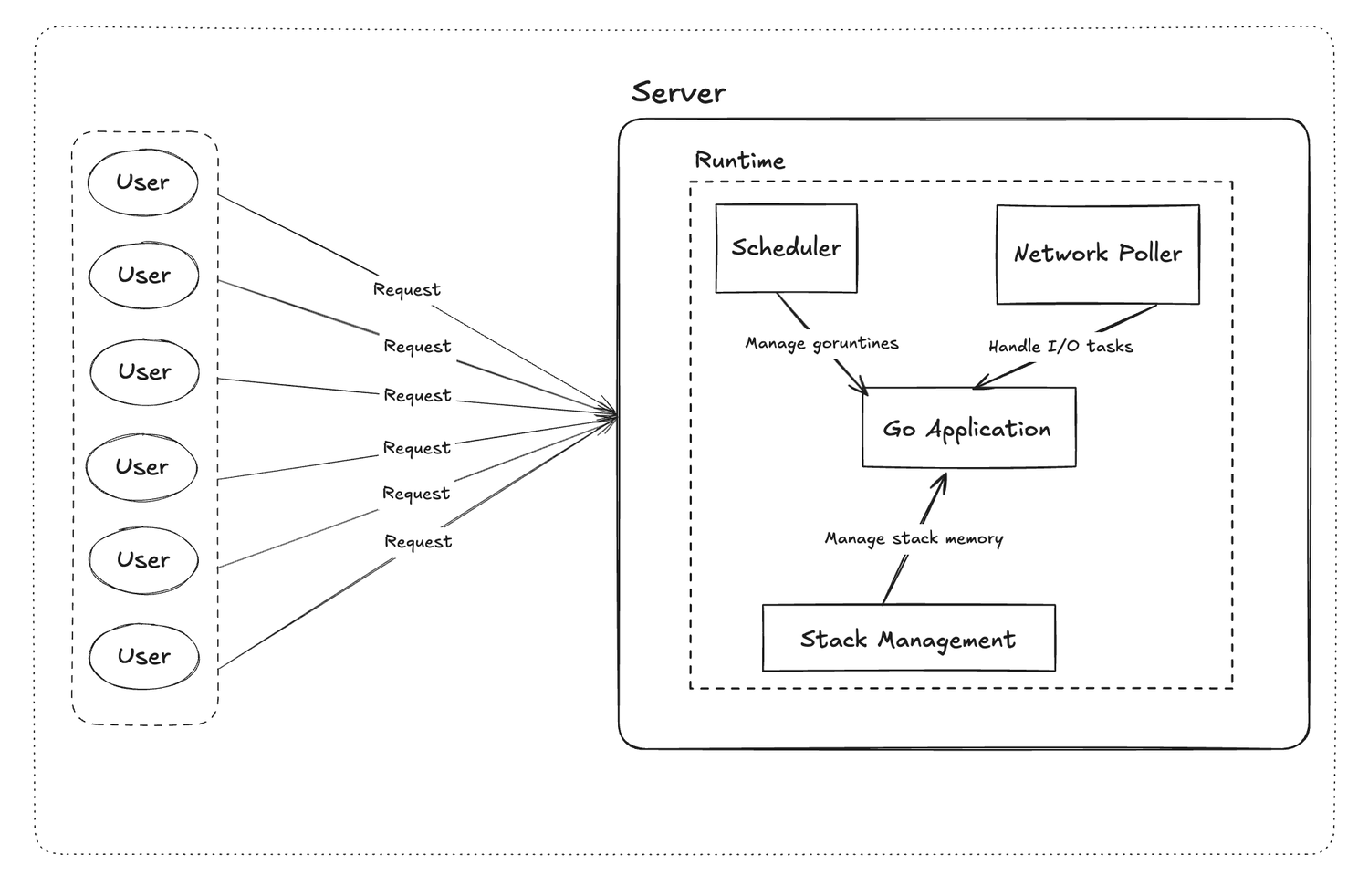
Go is renowned for its ability to handle thousands of concurrent requests efficiently, all while keeping performance high and resource usage low. But what’s the secret behind its power? In this post, I’ll break down the key aspects of Go’s runtime architecture that enable this remarkable scalability—so you can confidently explain, optimize, and leverage Go’s strengths in your own backend systems.
🚦 Why Does Go Scale So Well?
If you’ve ever wondered why Go can process massive numbers of concurrent requests while keeping infrastructure costs under control, the answer lies in its unique runtime design. Go’s concurrency model is not just about goroutines and channels—it’s a combination of a smart scheduler, efficient I/O handling, and memory management strategies that work together seamlessly.
🧠 The Scheduler: G, M, P Model
At the heart of Go’s concurrency model is its scheduler, which orchestrates work using three key components:
Goroutines (G): A lightweight, independently managed task. Goroutines are cheap to create (starting at ~2KB of stack space) and managed by the Go runtime, not the OS. This allows Go to run thousands of goroutines concurrently without overwhelming system resources.
Machine (M): An actual OS thread responsible for executing goroutines. Each M can run one goroutine at a time, but the Go runtime can switch between goroutines on the same M, allowing for efficient multitasking.
Processor (P): Holds a run queue of goroutines and coordinates their assignment to machines. The number of Ps is typically set to the number of available CPU cores, allowing Go to efficiently utilize all available processing power.
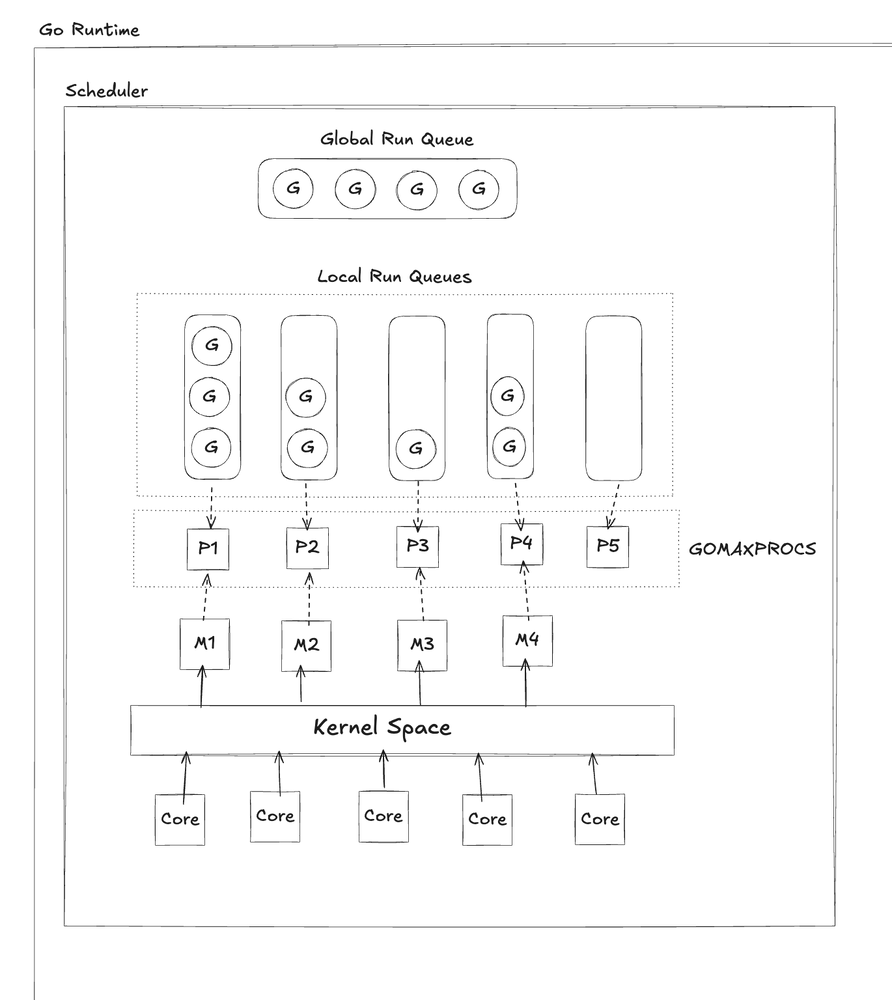
⚙️ How Does the Go Scheduler Work?
The Go scheduler is the brain behind all concurrency in Go applications. It is responsible for:
- Managing the execution lifecycle of goroutines (G).
- Assigning goroutines (G) to processors (P) for execution.
- Assigning processors (P) to machines (M), which are actual OS threads.
- Keeping execution efficient by minimizing idle threads and maximizing CPU utilization.
🔄 Multiplexing Goroutines (G) to OS Threads (M)
Let’s break down how the scheduler multiplexes thousands of goroutines onto a limited number of OS threads:
- Each processor (P) maintains its own local run queue of goroutines waiting to execute.
- When a new goroutine (G) is created by the application, it is added to the run queue of the current processor (P).
- If the processor (P) does not have an OS thread (M) assigned, the scheduler will assign one so the goroutines can be executed.
- If the local run queue of a processor becomes full, any extra goroutines are moved to the global run queue, shared among all processors.
- If another processor (P2) is idle, the scheduler assigns an available thread (M2) to it so it can start running goroutines.
🏃 Work Stealing and Efficient Scheduling
- If a processor’s local queue is empty, its OS thread (M) will attempt to “steal” goroutines from the run queues of other processors. This work stealing algorithm helps maximize CPU usage across all cores.
- If there’s nothing to steal, the thread checks the global run queue for available goroutines.
- Finally, if no tasks are available, the thread checks the network poller for goroutines that are blocked on I/O (e.g., waiting for network or disk operations to complete).
🧩 An Example in Action
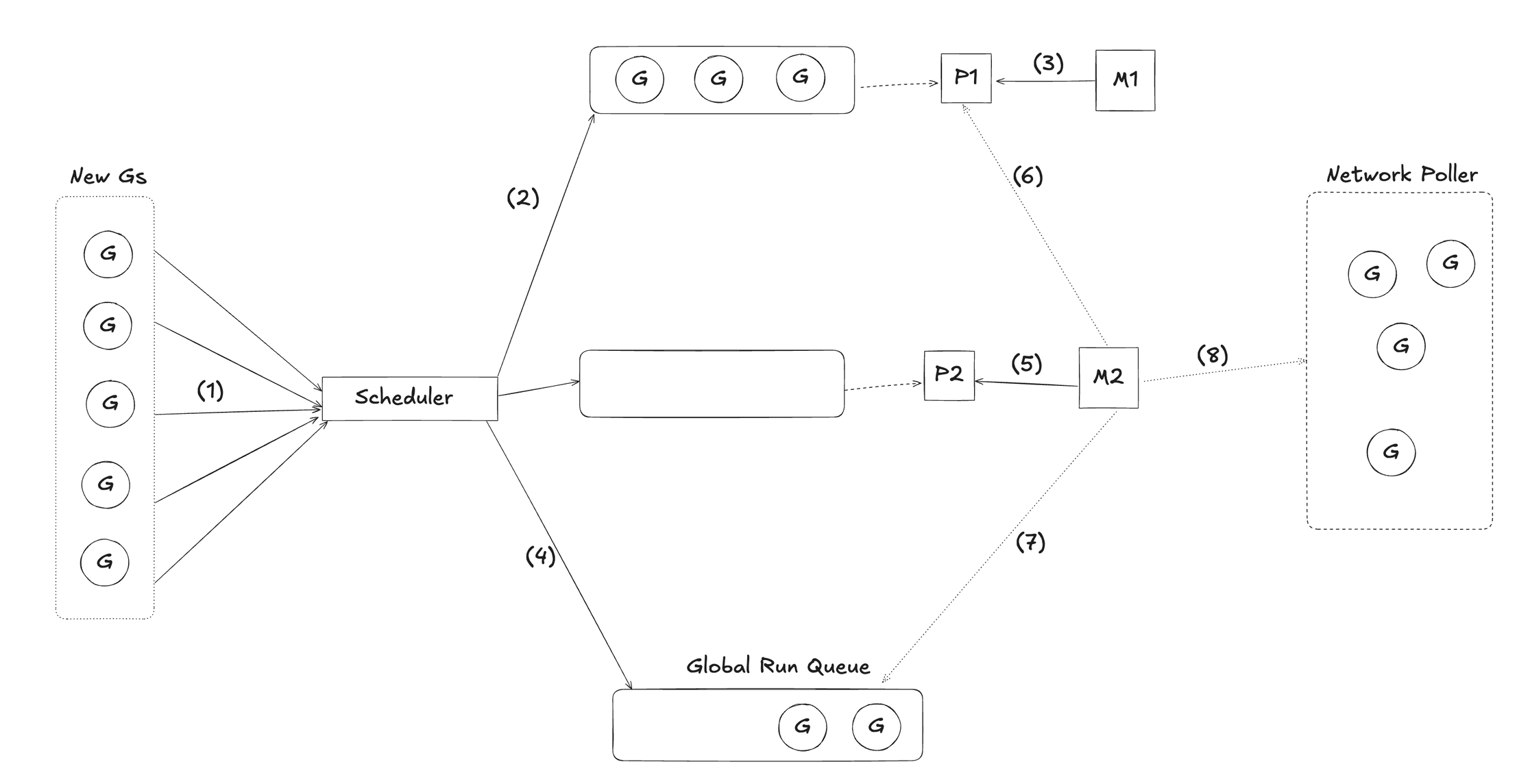
- Newly created goroutines (Gs) from the application are managed by the Go Scheduler.
- If there’s an available Processor (P1) running, the Scheduler will place the new Gs into P1’s local run queue.
- If P1 doesn’t have a Machine (M) assigned, the Scheduler will assign an OS thread (M1) to execute the Gs.
- If P1’s run queue is full, any excess Gs will be moved to the Global Run Queue, which is shared among all Processors.
- When the Scheduler detects another idle Processor (P2), it assigns a Machine (M2) to P2 to handle the workload.
- M2 will then use a work-stealing algorithm: if another Processor (like P1) has unprocessed Gs, M2 will “steal” some of them into its own queue.
- If there’s nothing to steal, M2 will check the Global Run Queue.
- And if there’s still no task to execute, M2 will look into the Network Poller to see if there are any I/O-ready goroutines that need to be resumed.
🚀 Go’s Scheduler Optimizations
Go’s scheduler uses several advanced techniques to achieve high performance and scalability:
- Work-stealing algorithm: Distributes load evenly and prevents CPUs from idling.
- Thread-local storage: Reduces contention between threads and improves memory access efficiency.
- Multi-core awareness: Ensures work is balanced across all available CPU cores to fully utilize modern hardware.
- Preemption: Allows the scheduler to interrupt long-running goroutines to ensure fairness and responsiveness, especially in I/O-bound applications.
🛜 Network Poller (Non-blocking I/O)
The Go runtime includes a sophisticated network poller that handles non-blocking I/O operations efficiently. This is crucial for applications that need to handle many simultaneous network connections without blocking threads.
🔧 Operation Mechanism
- When a goroutine (G) is blocked by an I/O operation, it goes to sleep and stops running.
- The thread (M) that was running G is released back to the thread pool, so it’s not wasted or blocked.
- The I/O request is handed off to the Network Poller, which uses platform-specific mechanisms like
epoll,kqueue, orIOCP. - If the current Processor (P) still needs a thread to run other goroutines, the Scheduler assigns a different thread (M) to it.
- Once the I/O is complete, the sleeping goroutine (G) is reactivated and placed back into the run queue.
- The Scheduler will run G again as soon as a thread is available.
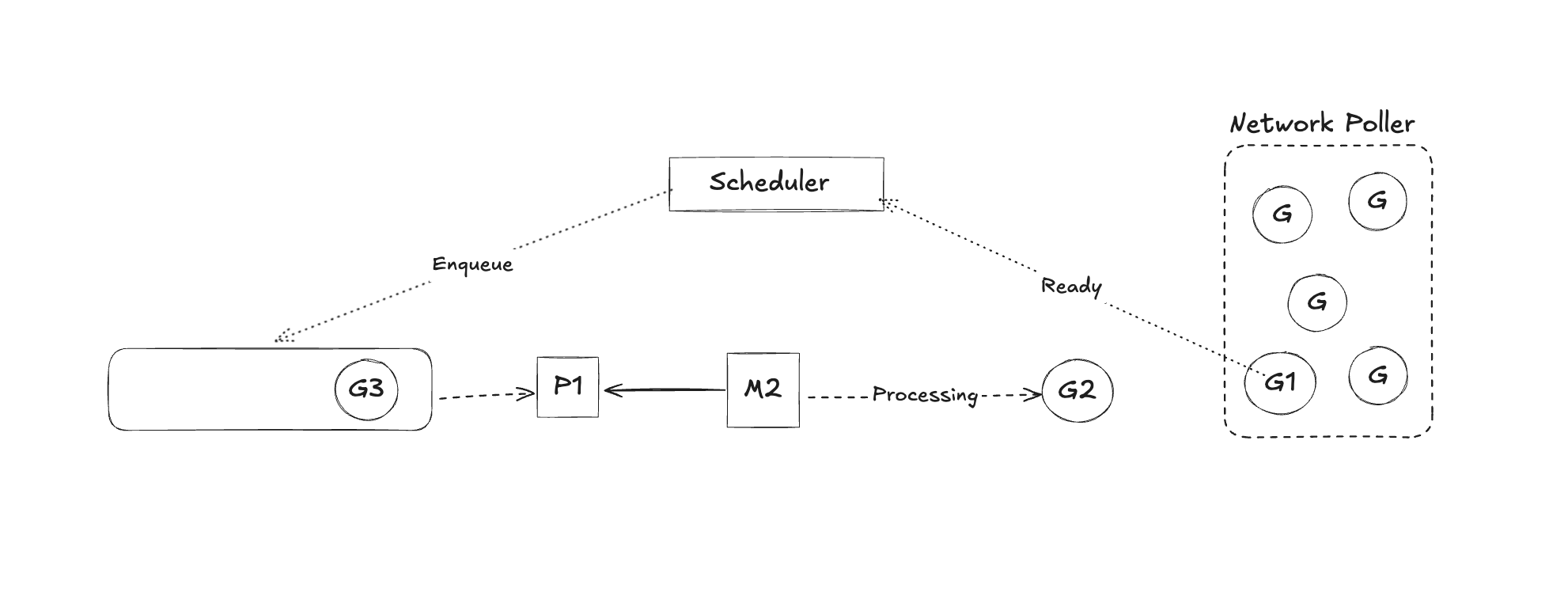
🧩 Example of Network Polling
- Step 1: Return M1 to the thread pool and register G1 with the Network Poller.

- Step 2: Scheduler will assign another thread (M2) to the Processor (P1) to continue executing other goroutines.
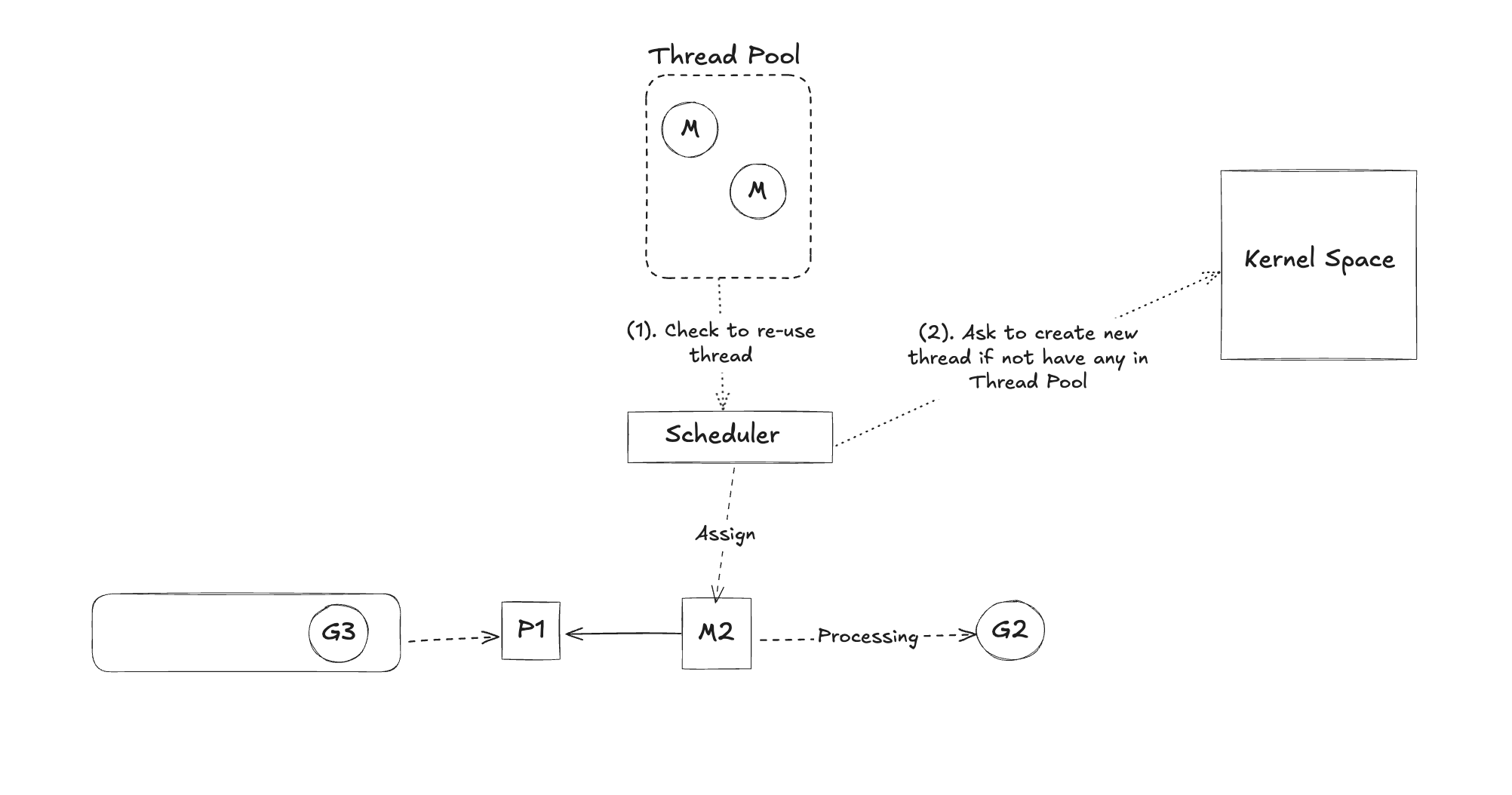
- Step 3: When the I/O operation completes, the Network Poller wakes up G1 and places it back into the run queue.
Benefits:
- Threads aren’t blocked → threads are reused efficiently.
- Scales to tens of thousands of connections without needing thousands of threads.
- I/O-bound applications run smoothly and efficiently.
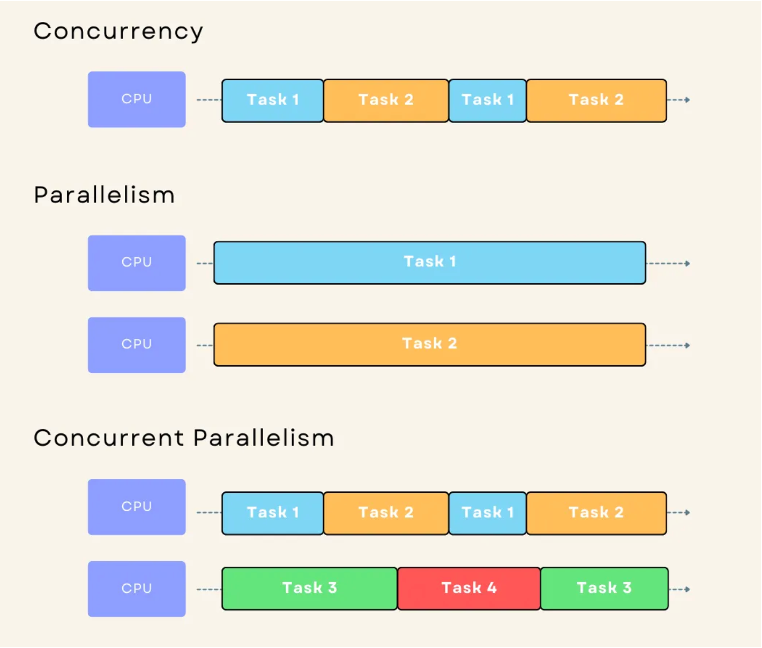
Now you can see why Go chose the M:N scheduling model, right?
Instead of assigning one OS thread per goroutine, Go smartly reuses threads and only creates new ones when absolutely necessary.
The result?
A system that can handle thousands of goroutines while staying optimized in terms of performance and resource usage.
This is the power of combining concurrency and parallelism — and it’s exactly why Go is lightweight, powerful, and highly efficient.
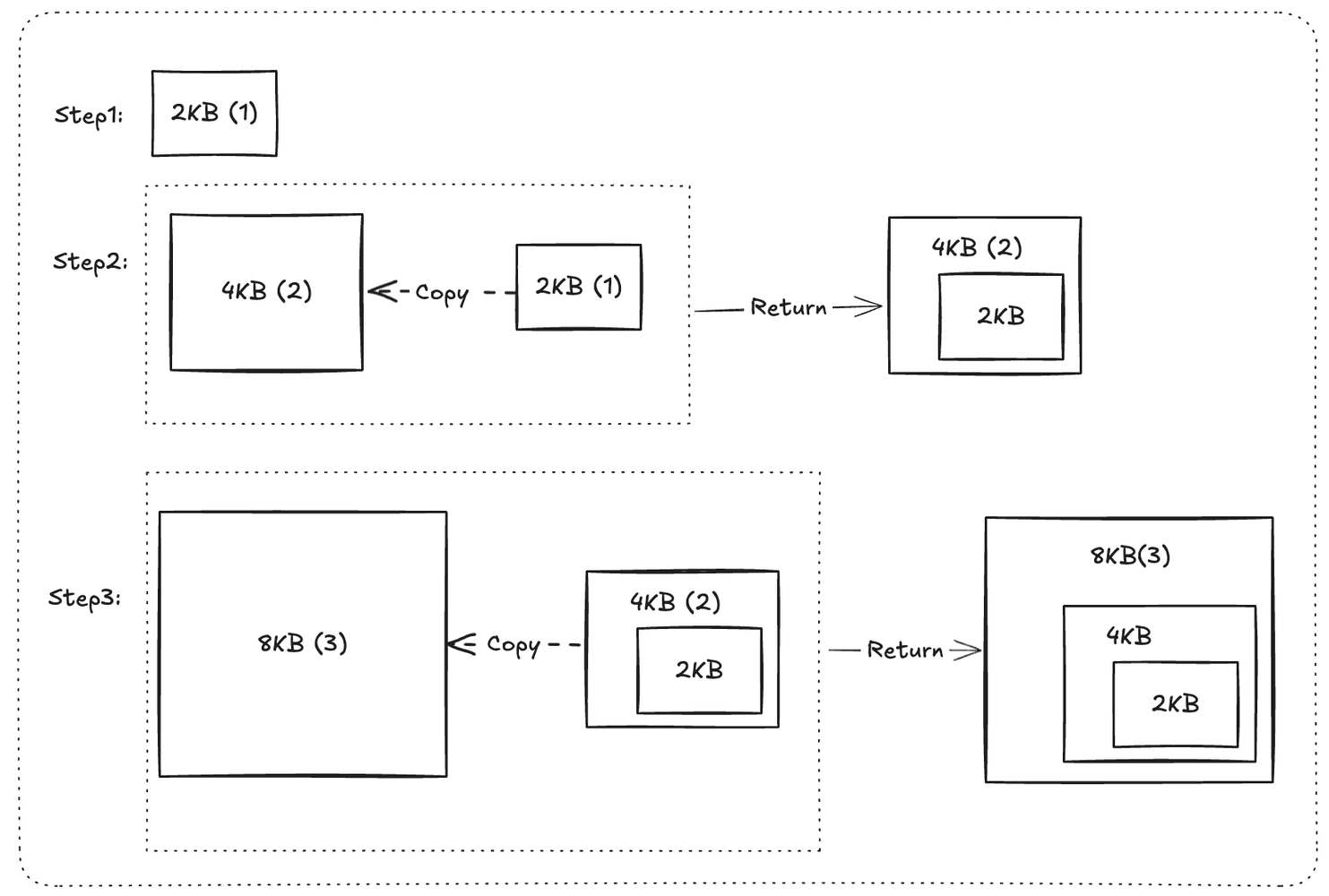
🛢️ Stack Management
Each goroutine starts with a very small stack (around 2KB), and it’s dynamically managed by the Go runtime:
- The stack can automatically grow or shrink based on the goroutine’s needs during execution.
- Go uses a split stack technique — memory is only allocated when truly needed, avoiding waste.
- It doesn’t rely on the fixed-size OS thread stack (~1MB per thread), which allows hundreds of thousands of goroutines to run without exhausting RAM.
- Each goroutine’s stack is separately allocated, not part of the thread’s stack — giving Go more control and better optimization.
🧩 Example of Stack Management
1
2
3
4
5
6
7
8
9
10
11
func deep(i int) {
if i == 0 {
return
}
deep(i - 1) // Recursive call, stack grows as needed
}
func main() {
go deep(100000) // This goroutine will use a small stack initially
time.Sleep(1 * time.Second) // Wait for the goroutine to finish
}
In this example, the deep function is recursive and will grow the stack as needed. Go’s runtime will automatically manage the stack size, allowing the goroutine to run without running into stack overflow issues.
Benefits
- Memory-efficient: Significantly reduces memory usage when running many small goroutines.
- Safe by design: Prevents stack overflow panics, a common issue in many other languages.
- Highly scalable: Supports massive scaling without the memory overhead typically associated with large numbers of threads.
🧠 Memory Management
Go’s memory management is designed to be efficient and automatic, which is crucial for high-performance applications. Here are the key aspects:
- Garbage Collection (GC): Go uses a concurrent garbage collector that runs in the background, minimizing pause times and allowing the application to continue running while memory is being cleaned up.
- Automatic Memory Management: Developers don’t need to manually allocate and free memory, reducing the risk of memory leaks and dangling pointers.
- Escape Analysis: The Go compiler performs escape analysis to determine whether a variable can be allocated on the stack or needs to be allocated on the heap. This helps optimize memory usage and performance.
- Memory Pools: Go provides memory pools for frequently used objects, reducing the overhead of memory allocation and deallocation.
🧩 Example of Memory Management
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
fmt.Println("Goroutine", i)
}(i)
}
wg.Wait() // Wait for all goroutines to finish
}
In this example, Go’s memory management automatically handles the allocation and deallocation of memory for the goroutines. The garbage collector will clean up any unused memory after the goroutines complete, ensuring efficient memory usage without manual intervention.

Benefits
- Automatic and efficient: Reduces the burden on developers to manage memory manually.
- Concurrent garbage collection: Minimizes pause times, allowing applications to remain responsive.
- Optimized memory usage: Escape analysis and memory pools help reduce overhead and improve performance.
- Scalability: Handles large numbers of goroutines without significant memory overhead.
🏁 Conclusion
Go’s runtime architecture is a masterpiece of design that combines lightweight goroutines, an efficient scheduler, and advanced memory management techniques. This allows Go applications to handle massive concurrency with minimal resource overhead, making it a top choice for modern backend systems.